在2026年英伟达GTC大会上,黄仁勋以一场近两小时的主题演讲,为AI推理时代的产业重构描绘出清晰蓝图。这场演讲中,“token”一词高频出现超过70次,成为贯穿全场的核心线索。从硬件架构革新到数据中心转型,从万亿级AI基建到企业经营逻辑,再到智能体与物理世界AI的融合,token始终是串联各项议题的锚点。
清华大学可持续社会价值研究院院长杨斌提出,token在AI领域的中文译名亟待统一。他早在年初便建议将token译为“模元”,以区别于区块链等场景中的其他译法。随着黄仁勋在演讲中正式提出“模元工厂经济学”,这一译名的必要性愈发凸显。杨斌指出,模元不仅是AI经济逻辑的核心度量单位,更是推动技术普惠的关键纽带。
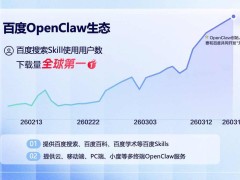
黄仁勋在演讲中强调,传统数据中心已从文件存储中心转型为模元生产工厂。在固定功耗下,模元的每秒吞吐量和单位成本直接决定AI企业的竞争力。模元兼具信息单位、算力单位和货币单位三重属性,成为AI时代的基础度量衡。全球大模型日均模元消耗量已达30万亿级别,中国模型调用量占比超60%,这一数据印证了模元作为智能经济核心指标的地位。
当前AI行业交流中,技术专家、企业高管和投资人普遍直接使用英文“token”,导致公众认知存在明显隔阂。杨斌分析,即便英文基础良好,非专业人士也难以准确理解token的核心要义;对于普通大众而言,生硬的英文术语更会加剧认知障碍。这种语言壁垒正在阻碍AI技术向千行百业的渗透。
此前,AI领域对token的中文译名存在多种尝试,如“词元”“语元”“义节”等,但均存在局限性。“词元”局限于文本场景,“语元”窄化了应用范围,“义节”过度聚焦语义,而音译如“托肯”则缺乏实义。这些译名无法承载token作为AI产业核心锚点的价值,难以打破大众认知壁垒。
杨斌提出的“模元”译法具有三大优势:一是对大众友好,无需专业背景即可感知其作为AI基础计量单位的属性;二是对产业实用,可直接对应模元消耗量、效率、成本等核心指标;三是对未来兼容,适用于智能体、多模态融合等全场景。他举例称,将“token工厂”改为“模元工厂”后,产业逻辑表达更加清晰流畅。
杨斌强调,推广“模元”译名并非咬文嚼字,而是为AI技术普及搭建语言桥梁。他呼吁学术界、产业界和媒体在相关讨论中统一使用这一译法,使模元成为理解、参与AI时代的日常用语。这一举措有望降低传统行业从业者接触AI的门槛,促进技术向更广泛领域渗透。