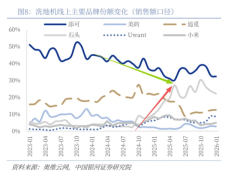
近日,一份由数巅科技发布的205页技术报告引发行业关注,该文档以系统化视角梳理了大语言模型从理论到落地的全链路技术体系,为数据智能的规模化应用提供了可复用的方法论。报告通过理论解析、技术拆解与案例实践三重维度,揭示了大模型如何重构传统AI开发范式,并推动智能技术向更普惠的方向发展。
在技术演进脉络中,报告指出大模型的核心突破源于参数规模的指数级增长与训练方法的迭代创新。从早期基于统计学的语言模型,到Transformer架构打破序列处理瓶颈,再到GPT-3通过千亿级参数验证涌现能力,技术路径清晰呈现"量变引发质变"的特征。国内科研力量在此领域表现突出,文心一言、ChatGLM等模型不仅在参数规模上比肩国际水平,更在中文语境理解、多模态交互等维度形成差异化优势。这些模型展现的少样本学习能力、上下文关联推理能力,正在重塑人机协作的边界。
构建高效训练体系是报告重点剖析的技术模块。针对大模型训练面临的算力瓶颈,文档详细拆解了分布式训练策略:数据并行通过切分训练样本提升吞吐量,模型并行则将神经网络层分配至不同计算节点,二者结合可支撑万亿参数模型的训练需求。为解决内存墙问题,混合精度训练、ZeRO优化等技术通过压缩存储占用与通信开销,使训练效率提升3-5倍。在架构层面,参数服务器与去中心化通信模式的对比分析,为不同规模团队提供了可适配的解决方案。
应用开发环节的革新同样值得关注。报告提出"Prompt工程替代子模型训练"的新范式,通过设计精准的指令模板,开发者可快速激活大模型的特定能力,这种敏捷开发模式使项目周期缩短60%以上。LangChain框架的组件化设计进一步降低开发门槛,其内置的记忆管理、工具调用等模块,支持快速构建智能问答、数据分析等应用。在效率优化方面,KV缓存技术通过复用中间计算结果减少推理延迟,vLLM框架则通过动态批处理提升GPU利用率,实测显示模型响应速度提升2-4倍。
为确保技术可靠落地,报告构建了多维评估体系。从知识完备性、伦理安全性到复杂推理能力,12项核心指标形成立体化评估矩阵。自动评估工具与人工审核的协同机制,既保证评估效率又控制质量风险。针对不同应用场景,分类任务采用F1值、回归任务使用MAE指标、生成任务则通过BLEU评分进行量化评估。MMLU、C-eval等权威基准测试的引入,为模型能力提供客观参照标准。
实践案例部分,个人知识库问答助手的开发流程具有典型示范意义。从需求分析阶段的场景定义,到数据清洗时的隐私保护处理,再到Prompt设计遵循的"清晰性、完整性、适应性"原则,每个环节都提供可操作的执行清单。部署环节对比了云服务与边缘计算的适配场景,指出模型轻量化与硬件加速的协同优化方向。这种端到端的案例解析,为传统企业数字化转型提供了可直接复用的技术路线图。