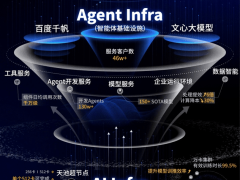
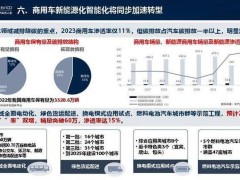
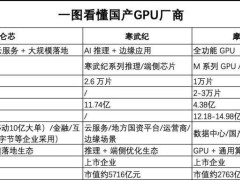
在通用人工智能(AGI)的探索之路上,持续学习能力被视为关键突破口。这种能力要求AI系统不仅能被动存储信息,更要像人类一样通过与环境交互实现认知进化。近期,由多家顶尖研究机构组成的联合团队提出了一种名为TTT-E2E(端到端测试时训练)的创新方法,为长上下文建模开辟了全新路径。
传统模型在处理长文本时面临两难困境:Transformer架构虽能捕捉远距离依赖关系,但其全注意力机制的计算成本随文本长度线性增长,导致处理超长序列时效率骤降;循环神经网络(RNN)和状态空间模型(SSM)虽能保持恒定推理延迟,却因固定压缩率导致信息丢失,难以维持长距离性能。研究团队试图打破这种非此即彼的局限,提出让模型在推理阶段实现动态学习。
TTT-E2E的核心创新在于将测试过程转化为在线优化过程。当模型读取上下文时,不仅执行前向传播预测下一个token,还同步进行梯度下降更新。这种设计使上下文信息直接编码进模型权重,而非依赖外部缓存存储。研究团队形象地比喻道:"就像人类阅读时不断修正认知模型,AI系统也能通过持续学习将知识内化为参数调整。"
为实现这一构想,研究团队开发了两项关键技术:通过元学习优化模型初始化参数,使系统具备"学会学习"的能力;采用混合架构结合滑动窗口注意力机制(SWA)和动态更新MLP层。其中,8K大小的滑动窗口负责处理局部信息,确保逻辑严密性;TTT更新的MLP层则承担长期记忆功能。为平衡计算开销,团队仅对最后四分之一Transformer块实施动态更新,并设计双MLP结构——静态层锁定预训练知识,动态层实现快速权重调整。
实验数据验证了该方法的显著优势。在30亿参数规模的模型测试中,TTT-E2E展现出与全注意力Transformer相近的性能曲线。当上下文长度从8K扩展至128K时,其他基准模型(如Mamba)在32K后性能显著下降,而TTT-E2E的损失函数持续降低。更引人注目的是推理效率:在128K上下文测试中,其处理速度比Transformer快2.7倍,且延迟不随文本长度增加而变化。
这项突破并非完美无缺。由于训练阶段需要计算二阶导数,TTT-E2E在短上下文场景下的训练速度明显慢于传统模型。研究团队提出解决方案:可通过微调预训练模型或开发专用CUDA内核来优化训练流程。在需要精确召回的任务中,全注意力模型仍占据优势,这印证了TTT-E2E更侧重于信息压缩与理解而非逐字存储的特性。
该研究的价值远超算法优化本身。通过将静态模型转化为动态学习系统,TTT-E2E为AI发展提供了新范式——模型处理长文档的过程实质上是微型自我进化。这种"以计算换存储"的思路,为构建能持续吸收人类文明知识的AI系统奠定了技术基础,有望突破硬件缓存限制,实现真正意义上的认知跃迁。