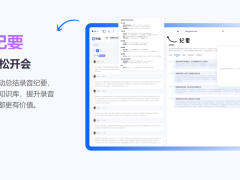
这套方案直击信息管理痛点:面对海量分散的文档、论文和代码,传统工具往往陷入"收藏即遗忘"的困境。卡帕西设计的系统通过三个核心环节实现突破:首先将原始资料导入指定文件夹,大模型自动完成内容解析、标签生成和知识图谱构建;其次通过Obsidian等可视化工具实现多维度检索;最终形成"输入-整理-输出-再归档"的闭环生态。
技术实现层面,该系统展现三大创新特性。其一,智能编译引擎能将杂乱无章的原始资料转化为结构化维基,自动生成摘要、建立反向链接并进行概念分类。其二,动态维护机制通过"Lint+Heal"功能定期扫描知识库,自动修正数据冲突、补充缺失信息,甚至通过外部检索完善知识体系。其三,双向交互接口既支持人类通过命令行或网页直接调用,又允许大模型高效检索内容,形成人机协同的知识处理网络。
实际应用中,这套系统已展现出惊人效能。卡帕西透露,在包含40万字研究资料的知识库中,系统无需复杂检索增强技术即可精准定位关键信息。更关键的是,所有查询结果都会自动归档,使知识库随着使用持续增值。这种"用进废退"的特性,让知识库真正成为会自我成长的"第二大脑"。
行业观察者指出,这种知识管理范式转移可能带来深远影响。传统大模型受限于上下文窗口,常出现"记忆衰退"问题,而知识库方案将临时记忆转化为永久存储,使模型只需掌握"知识坐标"而非完整内容。有技术评论员认为:"这相当于给AI装上了外部存储器,既降低了计算成本,又提升了信息处理的可持续性。"
目前,卡帕西已公开完整搭建教程,涵盖从数据导入到系统维护的全流程。特别值得关注的是,他开发的Obsidian Web Clipper插件可一键将网页转化为Markdown格式,并自动下载关联图片至本地,有效解决了网络内容依赖问题。随着越来越多开发者尝试部署,这种新型知识管理架构或将重塑人机协作的生产力图景。