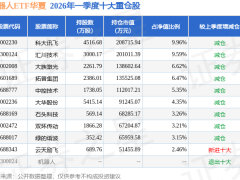
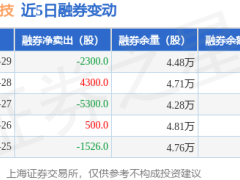
阿里云通义千问团队近日宣布推出Qwen3.7-Plus多模态智能体模型,该模型通过整合视觉与语言能力,构建了统一化的智能体基座架构。作为Qwen3.7系列的升级版本,新模型在保持原有文本处理与任务执行能力的基础上,创新性融入了视觉理解模块,支持图像、视频、屏幕界面及网页内容等多类型输入。
技术测试数据显示,Qwen3.7-Plus在全球权威视觉大模型评测平台Vision Arena中表现突出,综合得分位列全球第五、中国区榜首。该模型突破传统单模态限制,可在图形用户界面(GUI)和命令行界面(CLI)环境中自主完成复杂任务,例如通过分析屏幕截图理解软件操作流程,或根据视频内容生成交互指令。
实际应用场景中,基于Qwen3.7-Plus开发的Hybrid-Agent系统展现了强大能力。该系统曾持续运行11小时以上,独立完成英语单词学习应用的完整开发流程,涵盖需求分析、界面设计、代码编写到功能测试全环节。更令人瞩目的是,其复刻的macOS原生Stocks应用在交互逻辑与视觉呈现上达到高度还原,验证了模型在跨模态任务中的精准执行能力。
本报道所涉数据及信息均来自公开渠道整理,相关内容不构成任何形式的投资指引。市场参与者在使用前应通过官方渠道进行信息核验。